HackTheBox: Exatlon Challenge - Writeup
Published: 2021-05-28This is the box where I realised that “Easy” on HTB means “This is insane, send help” in real life (sometimes).
Initial overview
As always, we start out by downloading the binary, in this case exatlon_v1. It’s most definitely an ELF binary, but it’s a good idea to run file on it to get some initial information:
$ file exatlon_v1
exatlon_v1: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, no section headerAfterwards, let’s import it into Ghidra. One thing I learned since last time: Selecting All when analyzing a binary activates the Aggressive Instruction Finder, an experimental feature described as follows:
Finds valid code in undefined bytes that have not been disassembled.\ WARNING: This should not be run unless good code has already been found.\ YOU MUST CHECK THE RESULTS, IT MAY CREATE A LOT OF BAD CODE!
In this case, the AIF will not run in the first place:

I was surprised by this, but when looking at the binary in its current form, we can see that there are a whole lot of 00h values all over the place. It’s very clear that the binary has been compressed somehow. Searching for strings in Ghidra reveals exactly how:

UPX is an executable packer for a several executable formats, including ELF. After installing it separately and reading up on the man page, we can see that executing the command upx -d exatlon_v1 decompresses the previously compressed executable. Re-importing the file into Ghidra and analyzing with the Aggressive Instruction Finder should now work.
Initial analysis in Ghidra
Going through the Symbol Tree, we can see that our main() function is hidden away inside the ma... folder. Ghidra automatically organises functions into respective folders if there is a lot of them, like in this case with malloc, main, malloc_info, all starting with the letters ma.
Inside our main function are several interesting bits and pieces, including the visible entry point to Exatlon with the password prompt:
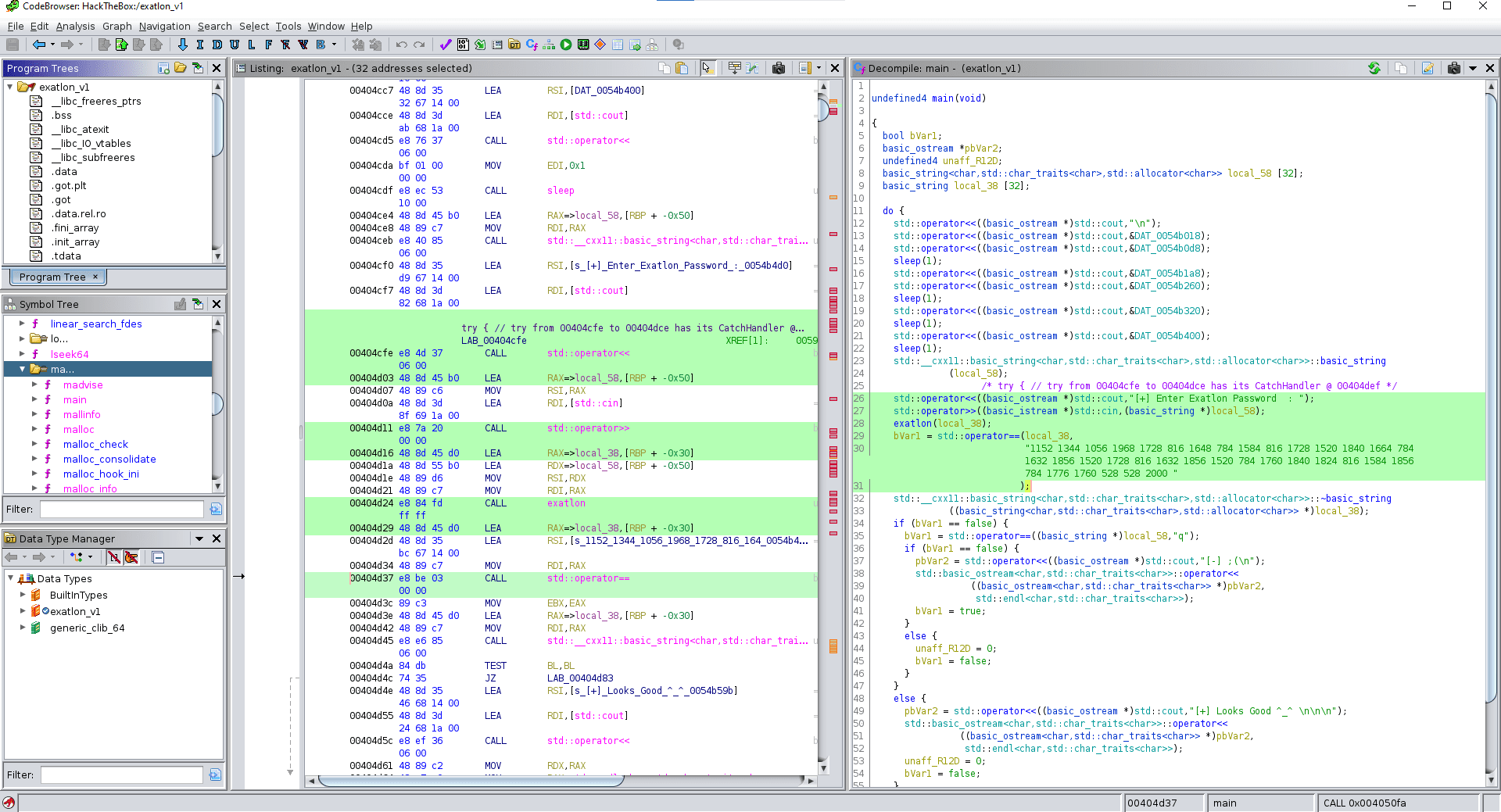
If you’ve never touched C++ before, std::cout writes to stdout, while std::cin takes input from stdin.
We’ll want to put our focus on the exatlon() function as well as the comparison with the long string of numbers. I initially thought that this was necessary to gain access to the flag, but if we take a look inside the branches of the if statement (same screenshot), we can see two things:
- As expected, if the comparison fails we are greeted with a negative output:
"[-] ;(" - If the comparison succeeds, we are only greeted with a positive output:
"[+] Looks Good ^_^"
There is no function call or similar to output any flag. This led me to assume that the numbers inside the comparison are actually the flag. And this is how the hard part started.
Making sense of the numbers
After playing around with the numbers for a while, it’s clear that they are not directly any “known” format. Taking a step back, we can see that right before our comparison the exatlon() function is called; this presumably encodes our input in a way similar to the numbers found in the comparison.
Let’s take a look at the function:
Ghidra is very verbose when it comes to decompiling these functions, so it becomes very hard to read, especially if you barely wrote any C++ in your life (like me) in the first place.
I backed out of trying to analyse that function pretty much straight away - I had some idea as to what’s going on, but I elected to go over to gdb to catch the result of the function instead.
Working with gdb
Working with gdb is relatively easy in theory. We can load up our program by calling gdb exatlon_v1. Breakpoints are set using b and we can pull the values from registers using info registers (a nice alternative is using layout reg if we want to observe register values over multiple steps). stepi moves one instruction forward, step one step. The difference between the two becomes apparent when hitting an internal function like a comparison operator: stepi will step through all internal instructions of that operator, while step will actually go one step forward inside the code as we read it.
As we want to analyze the returned value after the exatlon() function ran, let’s find an address where we can set our breakpoint.

In this case, 00404d2d seems like a good address to set a breakpoint at. We can do that by pointing to it and using the hex value: b *0x00404d2d.
Running the program now moves us forward to the password prompt. Let’s try the letter ‘A’. After hitting enter, we will immediately hit our breakpoint. Great! Taking a look at the registers, however, not so great:
Breakpoint 1, 0x0000000000404d2d in main ()
(gdb) info registers
rax 0x7fffffffe190 140737488347536
rbx 0x400548 4195656
rcx 0x20303430 540030000
rdx 0x7fffffffe0e8 140737488347368
rsi 0x7fffffffe0e8 140737488347368
rdi 0x7fffffffe0e8 140737488347368
rbp 0x7fffffffe1c0 0x7fffffffe1c0
rsp 0x7fffffffe170 0x7fffffffe170
r8 0x7fffffffe130 140737488347440
r9 0x4db290 5091984
r10 0x7fffffffdd94 140737488346516
r11 0x558028 5603368
r12 0x49ebe0 4844512
r13 0x0 0
r14 0x5a8018 5931032
r15 0x0 0
rip 0x404d2d 0x404d2d <main+257>
eflags 0x202 [ IF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0Imagine a whole bunch of question marks on my head when I saw that value of the access register RAX. Why is it a bunch of numbers? I was assuming that one letter would be four numbers at most. Did I miss something?
Turns out I did! Four days (!) and one existential crisis later, it turns out that we can actually cast register values before printing. So this works:
(gdb) p *(char **)$rax
$1 = 0x7fffffffe1a0 "1040 "I admit that I felt like a total idiot after that. Finding the return value of that function was hands down the hardest part of the challenge, and just because I didn’t know I could cast register values like that.
Gathering necessary data
We’re back in easy territory now, though! As we can see, our single character ‘A’ turned into the number 1040 after being processed by the exatlon() function. We can assume that other ASCII characters are processed similarly. Of course, we don’t want to spend all day painstakingly reconstructing the string that we found in the comparison operator by hand, so let’s fire up Python and get to work.
Here’s a list of what we need:
- A string (not a list!) of all ASCII characters (we are leaving out extended ones)
- The string found in the comparison operator that we want to decode
- The encoded values of all ASCII characters
Assembling a string of all ASCII characters
I chose to go with https://theasciicode.com.ar/ to find a list of all ASCII characters and just started typing them out in Python, from ! to ~. If you want to skip ahead, here’s a string with all basic ASCII characters:
"!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[]^_`abcdefghijklmnopqrstuvwxyz{|}~"We will use this string as our input in the program and then manually extract the encoded characters from the RAX register.
Saving the target string
The string found in the comparison operator is our “target” string that we want to decode. It looks like this:
"1152 1344 1056 1968 1728 816 1648 784 1584 816 1728 1520 1840 1664 784 1632 1856 1520 1728 816 1632 1856 1520 784 1760 1840 1824 816 1584 1856 784 1776 1760 528 528 2000"Gathering encoded values of our ASCII characters
Just like in the example above, we will again need to use gdb for this. After setting our breakpoint at *0x00404d2d and inputting all ASCII characters, we can fetch a list of the encoded characters by casting and printing RAX: p *(char **)$rax.
You’ll notice that perhaps the string will be cut short. This is because gdb limits the output to 200 characters. To remove that limit, we can run set print elements 0. It then looks like this:
(gdb) set print elements 0
(gdb) p *(char **)$rax
$2 = 0x5c3240 "528 1472 544 560 576 592 608 624 640 656 672 688 704 720 736 752 768 784 800 816 832 848 864 880 896 912 928 944 960 976 992 1008 1024 1040 1056 1072 1088 1104 1120 1136 1152 1168 1184 1200 1216 1232 1248 1264 1280 1296 1312 1328 1344 1360 1376 1392 1408 1424 1440 1456 1472 1488 1504 1520 1536 1552 1568 1584 1600 1616 1632 1648 1664 1680 1696 1712 1728 1744 1760 1776 1792 1808 1824 1840 1856 1872 1888 1904 1920 1936 1952 1968 1984 2000 2016 "Scripting our way to the flag
Armed with all of that info, we can finally move onto our Python script and decode the target string. I chose to be very verbose with the necessary variables:
plain = "!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[]^_`abcdefghijklmnopqrstuvwxyz{|}~"
plainList = list(plain)
allEncoded = "528 544 560 576 592 608 624 640 656 672 688 704 720 736 752 768 784 800 816 832 848 864 880 896 912 928 944 960 976 992 1008 1024 1040 1056 1072 1088 1104 1120 1136 1152 1168 1184 1200 1216 1232 1248 1264 1280 1296 1312 1328 1344 1360 1376 1392 1408 1424 1440 1456 1472 1488 1504 1520 1536 1552 1568 1584 1600 1616 1632 1648 1664 1680 1696 1712 1728 1744 1760 1776 1792 1808 1824 1840 1856 1872 1888 1904 1920 1936 1952 1968 1984 2000 2016"
allEncodedList = allEncoded.split(" ")
target = "1152 1344 1056 1968 1728 816 1648 784 1584 816 1728 1520 1840 1664 784 1632 1856 1520 1728 816 1632 1856 1520 784 1760 1840 1824 816 1584 1856 784 1776 1760 528 528 2000"
targetList = target.split(" ")Now, we will want to map an encoded character to the plaintext ASCII. To do that, we can simply use map(), a lambda function and our two lists:
result = list(map(lambda x, y: dict(character=x,encoded=y), plainList, allEncodedList))This will give us a list of dictionaries containing one plaintext character and one encoded character. Note that for this to work, the plaintext characters have to match up exactly to their encoded version, so make sure the input is structured accordingly.
After having the list, it is simply a matter of iterating through the target string, matching the encoded character with the created dictionary and output the result. I solved this with a for loop, but this being Python, I’m sure it could be structured more elegantly. The final version of the script looks like this:
plain = "!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[]^_`abcdefghijklmnopqrstuvwxyz{|}~"
plainList = list(plain)
allEncoded = "528 544 560 576 592 608 624 640 656 672 688 704 720 736 752 768 784 800 816 832 848 864 880 896 912 928 944 960 976 992 1008 1024 1040 1056 1072 1088 1104 1120 1136 1152 1168 1184 1200 1216 1232 1248 1264 1280 1296 1312 1328 1344 1360 1376 1392 1408 1424 1440 1456 1472 1488 1504 1520 1536 1552 1568 1584 1600 1616 1632 1648 1664 1680 1696 1712 1728 1744 1760 1776 1792 1808 1824 1840 1856 1872 1888 1904 1920 1936 1952 1968 1984 2000 2016"
allEncodedList = allEncoded.split(" ")
target = "1152 1344 1056 1968 1728 816 1648 784 1584 816 1728 1520 1840 1664 784 1632 1856 1520 1728 816 1632 1856 1520 784 1760 1840 1824 816 1584 1856 784 1776 1760 528 528 2000"
targetList = target.split(" ")
result = list(map(lambda x, y: dict(character=x,encoded=y), plainList, allEncodedList))
chars = []
for c in targetList:
chars.append(next(item for item in result if item["encoded"] == c)["character"])
print("".join(chars))And with this, we have our flag!
Conclusion
The initial sentence was a bit of an exaggeration, since the challenge is actually pretty easy, if you know how to properly read registers in gdb. I learned quite a bit from this, and as always, it was pretty fun.